
s5unnyjjj's LOG
Code Review: End-to-End Object Detection with Transformers - 작성 중(Updated 24.05.26) 본문
Code Review: End-to-End Object Detection with Transformers - 작성 중(Updated 24.05.26)
s5unnyjjj 2024. 3. 19. 19:44End-to-End Object Detection with Transformers 논문에서 제안하는 DEtection TRansformer(DETR) 모델 구조를 코드와 함께 리뷰해보려 한다.
Paper: https://arxiv.org/abs/2005.12872
Offifical github: https://github.com/facebookresearch/detr/tree/main
GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers. Contribute to facebookresearch/detr development by creating an account on GitHub.
github.com
DETR 논문의 큰 특징은 두가지이다.
- 트랜스포머 기반의 object detection 모델
- 이분매칭을 이용한 학습
우선, detr 모델에 대해서 설명 후에 이분매칭에 대하여 설명한다.
*** 트랜스포머 기반의 object detection 모델
▶ detr.py 함수 설명
● 아래처럼 detr.py 함수를 보면 짧다.

● 그래서 간단하게 구역을 나누고 그림으로 표현해보았다. 크게 6구역을 나눌 수 있다.
● 이제부터 차근차근 살펴본다.
● 1번구역을 보면 입력값을 nested_tensor_from_tensor_list함수를 이용하여 NestedTensor 타입으로 변경한다. NestedTensor가 어떤 타입인지부터 확인해본다.
---------------- 1번 구역 설명 시작 ----------------
▶ NestedTensor 클래스 설명
● NestedTensor라는 클래스는 tensors랑 mask로 이루어져있고 to 함수를 통해 합칠수도 있고, decompose 함수를 통해 분해할 수도 있다.
● 이제 NestedTensor의 tensors와 mask는 어떤 의미를 갖는지 변환 함수인 nested_tensor_from_tensor_list함수를 살펴본다.
▶ nested_tensor_from_tensor_list 함수 설명
● 우선 입력으로 받는 tensor_list는 각각의 원소가 torch_tensor인 것들로 구성된 리스트이다. tensor_list 각각의 원소는 입력으로 받는 이미지 하나하나를 의미한다. 그러므로 tensor_list는 batch size만큼의 크기를 갖는다. 즉, len(tensor_list) = batch size이다.
● Line 316에서 _max_by_axis 함수는 각 열에서 최대 값을 추출하는 함수이다.

● 쉽게 설명하기 위해 아래 그림을 그렸다.
● tensor_list 각각은 이미지 하나하나를 의미하기에 각 원소의 shape은 channel, height, width이다.
● _max_by_axis함수를 쉽게 설명하기 위해 오른쪽에 예시를 작성해보았다. batch size가 2라고 가정하면 2개의 원소가 있다. [3, 800, 1201]과 [3, 873, 800] 이다. 첫번째 열에서 최대값은 3, 두번째 열에서 최대값은 873, 세번째 열에서 최대값은 1201이므로, 해당 함수를 통해 도출되는 최종 값은 [3, 873, 1201]이다.

● 직접 코드도 구동해보았다. batch size를 2로 설정하였기에 두 배열만이 출력된다.(쉬운 설명을 위해 앞으로도 batch size는 2로 잠시 고정한다.) 두 배열의 _max_by_axis함수를 구동한 결과, [3, 873, 1201]가 나오는 것을 확인할 수 있다.
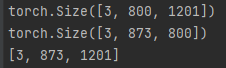
● Line 318~319: len(tensor_list)는 batch size이고, _max_by_axis 함수를 통해 나온 결과 값인 max_size를 더해주면 batch_shape = [2, 3, 873, 1201] 이다.
● Line 322~323: tensor는 shape이 [2, 3, 873, 1201]이며 0으로 채워지고, mask는 shape이 [3, 873, 1201]이며 1(True)로 채워진다. 그림으로 그리면 아래와 같다.
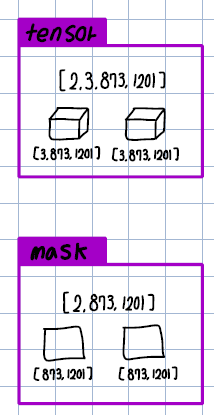
● Line 324~326
- 0으로 채워진 pad_image에 첫번째 이미지의 픽셀 값을 첫번째 이미지 사이즈(3, 800, 1201)만큼 채워주고, 두번째 이미지의 픽셀 값을 사이즈(3, 873, 800)만큼 채워준다. pad_iamge의 각 원소는 크기가 (3, 873, 1201)이기에 각 이미지 픽셀 값을 채워준 나머지 값은 당연히 0이 되게 된다.
- 1(True)로 채워진 m에 첫번째 이미지 사이즈(3, 800, 1201)만큼 0(False)로 채워주고, 두번째 이미지 사이즈(3, 873, 300)만큼 0(False)로 채워준다. m의 각 원소의 크기가 (873, 1201)이기에 각 이미지 사이즈외의 나머지 값은 당연히 1이 되게 된다.
● 그림으로 그리면 아래와 같다. 이렇게 나온 두 값은 각각 NestedTensor의 self.tensors와 self.mask가 되는 것이다.
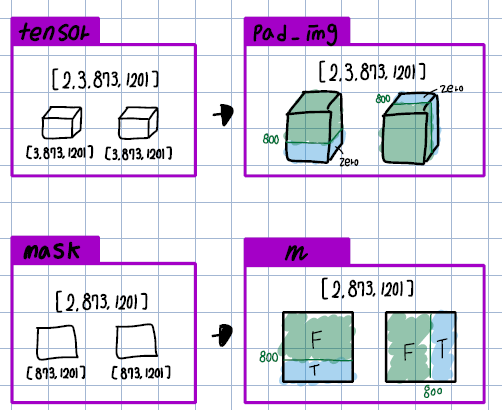
● 여기서 궁금할 것이다. 대체 왜 NestedTensor를 이용하여 각각은 최대값을 가져야하는것인가? 그림을 다시 살펴보면 pad_img의 각각의 원소는 입력값인 tensor_list와 다르게 고정된 크기를 갖게 된다. 고정된 크기를 왜 가져야만 할까? 해당 값이 어디에 사용되는지를 살펴보면 된다.
● detr.py의 Line 60~61을 보면 NestedTensor로 변환된 값이 self.backbone의 입력으로 들어가게된다. 즉, self.backbone을 통해 특징을 추출하려면 입력값은 고정된 크기를 가져야만한다. 그러므로 위에서 NestedTensor를 이용하여 고정된 크기로 변환시켜준 것임을 알 수 있다.
---------------- 1번 구역 설명 끝 ----------------

---------------- 2,3번 구역 설명 시작 ----------------
● 2번구역을 보면 입력값을 self.backbone 함수를 이용하여 features와 pos를 return 한다.
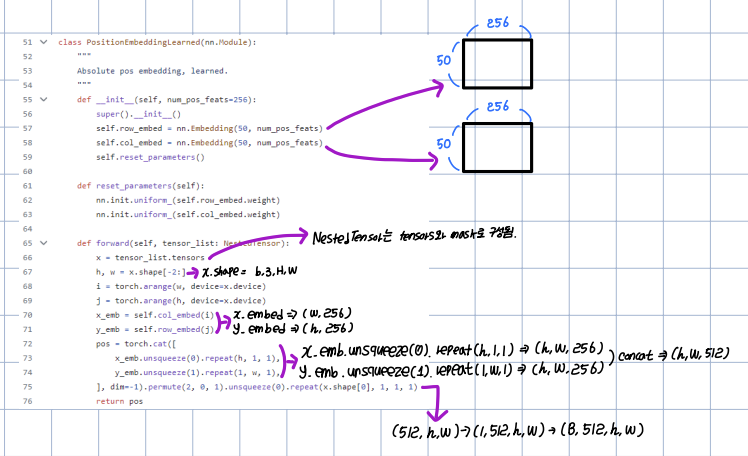
backbone.py를 확인해보면 feature와 pos는 아래와 같다. - features: backbone 내 네 개의 층(layer1, layer2, layer3, layer4)의 output을 담는다. - pos: features처럼 네 개의 층에 해당하는 위치정보를 담는다. 즉, build_position_encoding 함수를 이용하여
PositionEmbeddingSine 또는 PositionEmbeddingLearned 클래스를 통한 output을 담는다.
● 3번구역을 보면 decompose 함수를 이용하여 src와 mask로 분해한다
- features에는 backbone의 각 층에서 추출된 모든 특징을 다 포함한다. 하지만 transformer에는 최종 층에서 추출된 특징만 들어가기에 -1을 통해 최종 값만을 가져온다.
- 그다음 decompose 함수를 사용하는데 그 이유는 위에서 봤듯이 NestedTensor는 tensors와 mask로 이루어져 있다. 실제 픽셀값은 tensors에만 속해있기에 해당 값만을 transformer의 입력으로 사용되기에 분해해준다.
---------------- 2,3번 구역 설명 끝 ----------------
● 4번구역을 보면 이제 transformer가 시작된다.

---------------- 4번 구역 설명 시작 ----------------
▶ Transformer 클래스 설명

1. 입력값 차원 변경
- src: (b,c,h,w) -> (hxw, b,c)
- pos_embed: (b,c,h,w) -> (hxw, b,c)
- query_embed: (100, 512) -> (100, 1, 512) -> (100, b, 512)
- mask: (b,h,w) -> (b, hxw)
- tgt: torch.zeros(query_embed) -> (100,b,512)
2. TransformerEncoder
- TransformerEncoder에서 입력 변수 명이 변한다.
- src -> src
- mask -> src_key_padding_mask
- pos_embed -> pos
- EncoderLayer를 num_encoder_layer(=6)만큼 반복한다.
2-1. TrasnformerEncoderLayer
- E-MHSA(Encoder MultiHead Self-Attention)
- Q,K: output(src) + pos, V: output(src)
- Q, K에 들어가는 값은 pos가 더해져서 순서 정보가 고려된 값이다.
- 여기서 pos는 backbone을 통해 추출된 특징으로 position encoding한 값이다.
- MHSA는 Q,K간의 유사도를 V에 반영하고, attention matrix 정확도 향상을 위하여 멀티헤드를 사용한다.
3. TransformerDecoder
- TransformerDecoder에서 입력 변수 명이 변한다.
- tgt -> tgt
- memory -> memory
- mask -> memory_key_padding_mask
- pos_embed -> pos
- query_embed -> query_pos
- DecoderLayer를 num_decoder_layer(=6)만큼 반복한다.
3-1. TransformerDecoderLayer
- MHSA -> ... -> MHCA
- D-MHSA(Decoder MultiHead Self-Attention)
- Q, K: output(tgt) + query_pos, V: output(tgt)
- tgt는 query_pos와 동일한 모양의 텐서를 생성하며 0으로 초기화한값이다.
- 여기서 queyr_pos는 위치 정보를 어떻게 표현하는게 좋은지를 스스로 학습하기 위하여 tgt로 position embedding한 값이다.(nn.Embedding을 사용한다.)
- D-MHCA(Decoder MultiHead Cross-Attention)
- Q: tgt2(직전값) + query_pos, K: memory + pos, V: memory
- 초기에 0으로 초기화된 tgt에 값을 채워넣기위해 찾아야하므로 해당 값하고 위치 정보가 합해져서 Q에 들어간다.
- tgt는 이미지 특징 정보를 기반으로 표현되어진 encoder값을 통해 찾아야하므로, Encoder를 통해 입력 시퀀스의 표현이 저장된 memory값과 위치 정보가 합해져서 K에 들어간다.
- Q와 K간의 유사도를 encoder의 output에 반영하기위하여 memory가 V에 들어간다.
4. 최종 output
- [0]: hs.transpose(0, 1) : (1,100,b,512) -> (1,b,100,512)
- [1]: memory.permute(1,2,0).view(bs,c,h,w): (hxw,b,c) -> (b,c,hxw) -> (b,c,h,w)
---------------- 4번 구역 설명 끝 ----------------
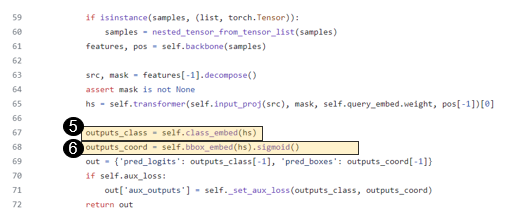
---------------- 5,6번 구역 설명 시작 ----------------
- 5번구역을 보면 self.class_embed 함수를 통과한다.
- hs: (1,b,100,512) -> outputs_class: (1,b,100,class+1)
- 추후에 out에 outputs_class[-1]인 (b,100,class+1)이 들어간다. 100개의 쿼리 각각은 분류 클래스 만큼의 방 개수를 갖고 있고, 해당 방들 중에 제일 높은 값을 가진 것이 최종 분류 종류가 될 것이다.(이 부분은 postprocess에서 처리된다.)
- 6번구역을 보면 self.bbox_embed 함수를 통과한다.
- hs: (1,b,100,512) -> outputs_coord: (1,b,100,4)
- 추후에 out에 outputs_coord[-1]인 (b,100,4)가 들어간다. 100개의 쿼리 각각은 4개의 박스 정보(center_x,center_y,height,width)를 갖고 있기에 4로 표현된다.
---------------- 5,6번 구역 설명 끝 ----------------
- detr.py에서 detr 모델의 설명은 끝났다. 모델을 통해 나온 output은 postprocess함수를 통해 최종 결과를 도출한다. 여기서 최종 결과는 필수적인 정보인 score, label, box 정보이다. 모델을 통해 나온 output은 후보군들이고 postprocess를 통해 후보군들중에 최종 결과를 반환하게 된다.

▶ PostProcess 클래스 설명
- out_logits: (b,100,class+1)
- F.softmax(out_logits, -1) -> (b,100,class+1)
- prob[..., :-1].max(-1) -> (scores,labels)
- 이로써 제일 큰 score를 가진 결과만이 산출되는 것이다
- out_bbox: (b,100,4)
- box_ops.box_cxcywh_to_xyxy -> (b,100,4)
- target_sizes_unbind(1) -> img_h, img_w
- torch.stack([img_w, img_h, img_w, img_h], dim=1) -> scale_ft
- boxes*scale_fct[:, None, :] = boxes
- 이미지 크기에 맞춰 박스 크기 조정하는 작업이다.
모델 설명은 끝이다. 이제 이분매칭을 이용한 학습에 대해서 설명한다.
*** 이분매칭을 이용한 학습
▶ SetCriterion함수 설명

- self.matcher는 matcher.py의 HungarianMatcher이다. HungarianMatcher를 통해 indices를 받아와서 indices에서 매칭된 인덱스를 이용하여 각 loss를 계산 후, loss와 weight를 업데이트 해준다.
▶ HungarainMatcher함수 설명
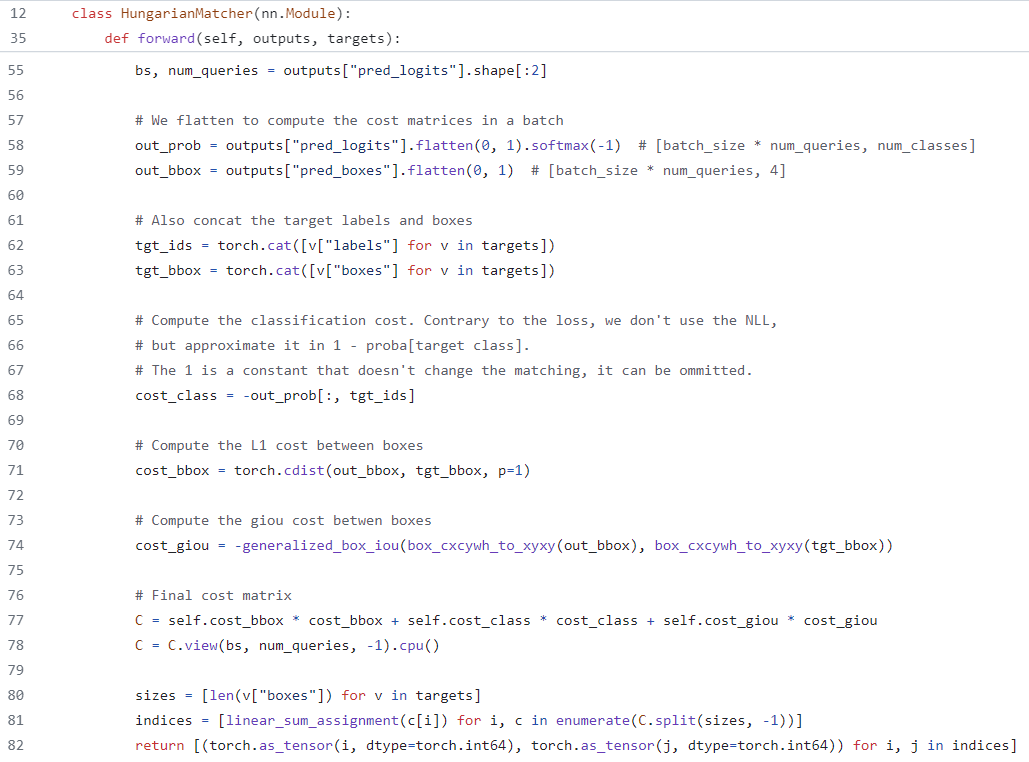
- STEP1. Hungarian Loss를 계산한다.
- Hungarian Loss는 cost_class와 cost_bbox와 cost_giou를 이용하여 계산된다.
- cost_class: label 계산을 위한 것으로, 논문에서는 CE(Cross Entropy) loss를 이용하여 계산되지만, cost matrix를 계산할때는 log를 빼고 계산된다.
- cost_bbox: target box와 pred box를 L1 loss를 이용하여 계산한 값이다.
- cost_giou: 박스 계산에 L1 loss만 사용하게 되면 발생하는 한계때문에 같이 사용되는 것이다. GIoU는 Generalized IoU의 약어로, pred box와 target box가 안 겹치는 경우 어느 정도의 오차로 안겹치는지 파악하기 위한 용도로 사용된다. GIoU가 클수록 좋은것이기에 Loss로 사용할때는 (1-GIoU)가 사용된다.
- STEP2. 계산한 Hungarian Loss 값을 이용하여 Cost Matrix를 생성한다.
- 여기서 변수 C가 cost matrix를 의미한다.
- STEP3. Hungarian Algorithm을 사용하여 매칭된 인덱스를 반환한다. (반환한 값은 위의 SetCriterion에서 활용되어 loss를 계산해주는 것이다.)
작성중입니다.(Last Updated 24.05.26)
>> 위 내용은 필자가 홀로 공부하며 학습한 내용입니다.
>> 부족한 점이 많을 수 있기에 잘못된 내용이나 궁금한 사항이 있으면 댓글 달아주시기 바랍니다.
>> 긴 글 읽어주셔서 감사합니다.
'Review (Paper, Code ...) > Code Review' 카테고리의 다른 글
| Code Review: Detection using ImageAI (0) | 2022.05.05 |
|---|---|
| Code Review: Vision Transformer (Tensorflow version) (0) | 2022.04.29 |
| Code Review: Vision Transformer (Ref: Google research github) (0) | 2022.04.01 |


